heat
AI data centers are constrained by power and chip supply.
Chips: Demand scales in months to years. Designed by NVIDIA and AMD. Efficiency is set at silicon level years before a server ships
Power: Supplied by the grid and scales in years to decades. Moves slowly due to permitting time, transmission infrastructure etc
The biggest lever for data centers is how much useful compute they extract per watt. Once a data center is built, every watt is used for two jobs: compute and overhead. The majority of overhead goes towards heat management.
Every watt spent moving heat is a watt not spent on compute.
Heat is a three-layer problem.
Layer 1 - Chip density. Hardware design and its power needs set by chipmaker
Layer 2 - Heat off the source. Heat is generated at the die. So you’d want to pull it off the source fast before it spreads into surrounding hardware
Layer 3 - Heat out of the room. Once heat leaves the chip, it has to leave the building
There are two established ways to remove heat from a data center building.
Air cooling:
Cheap to build and easy to operate. Fans push cold air across hot hardware, chillers cool the air, rinse and repeat
The problem is physics. Air has low thermal capacity as it can only carry so much heat per cubic meter. Once a rack crosses 50 kW, air physically cannot remove heat fast enough no matter how hard the fans blow. The chips overheat not because something broke but because the medium hit a wall
Air cooling was great before 2022. A standard server rack drew up to 20+ kW and air could handle it. Then AI happened. The modern AI GPU rack is more dense and draws more power (120 kW). Air cooling was never designed for these rack densities and is approaching its practical limits
Liquid cooling:
Coolant runs directly to the chip via cold plates or hardware is submerged in fluid entirely
Liquid carries roughly 3500 times more heat per liter than air, meaning a cooling loop the size of a garden hose moves more thermal energy than an entire raised-floor air system
Liquid unlocks a denser AI chip hardware design. Racks can run hotter. This is why NVIDIA’s the NVL72 with 72 GPUs in a single rack drawing 120 kW exists at all. Without liquid cooling, it’s physically impossible to build
Economics only work for new builds. Retrofitting liquid into an existing air-cooled facility is hard, eg construction, downtime and millions of dollars of capex. Most operators run the numbers and stay on air
As chip power density increases, the heat problem concentrates at the die faster.
Both air and liquid remove heat after it leaves the chip. Neither touches it at the source. Until recently, most investment focused on the former.
Diamond cooling works at the chip source and is complementary to air and water cooling.
Concentrated heat is hard to remove. Synthetic diamonds have the highest thermal conductivity, roughly 5x copper. Diamonds spread the heat over a larger area making heat easier to dissipate. The die runs cooler and stays under its thermal limit instead of throttling. Cooler silicon leaks less electricity, so the chip does the same work for fewer watts. And with room to spare before it overheats, it can run flat-out and get more work done.
Synthetic diamond is now an order of magnitude cheaper to produce than it was fifteen years ago and the price is still falling.
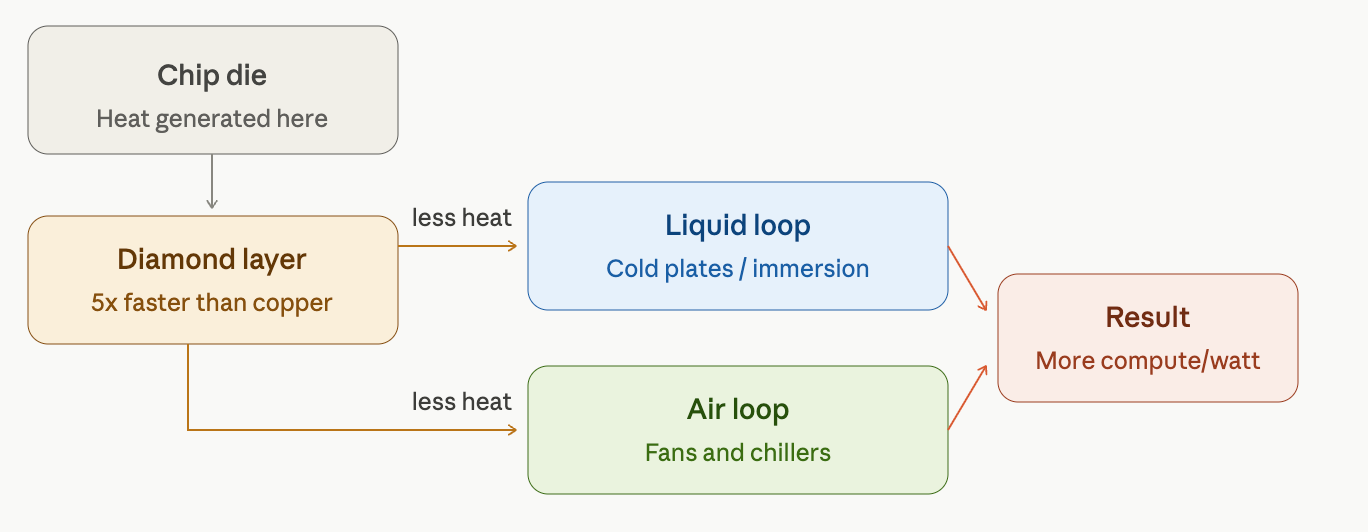
The diamond layer changes the economics for running servers and data centers.
Server economics:
Every GPU has a thermal ceiling. Push past it and the chip throttles. When the temperature rises even more, the chips fail
Lower operating chip temperatures mean longer hardware lifespan, lower replacement costs, longer usable life per server
Data center economics:
A standard air-cooled data center operates at roughly 75°F. The facility keeps the room cool to prevent exactly what we described above
Raising the data center's operating temperature means less power is required to move heat around the room. That spare power goes back into the available budget to power more compute
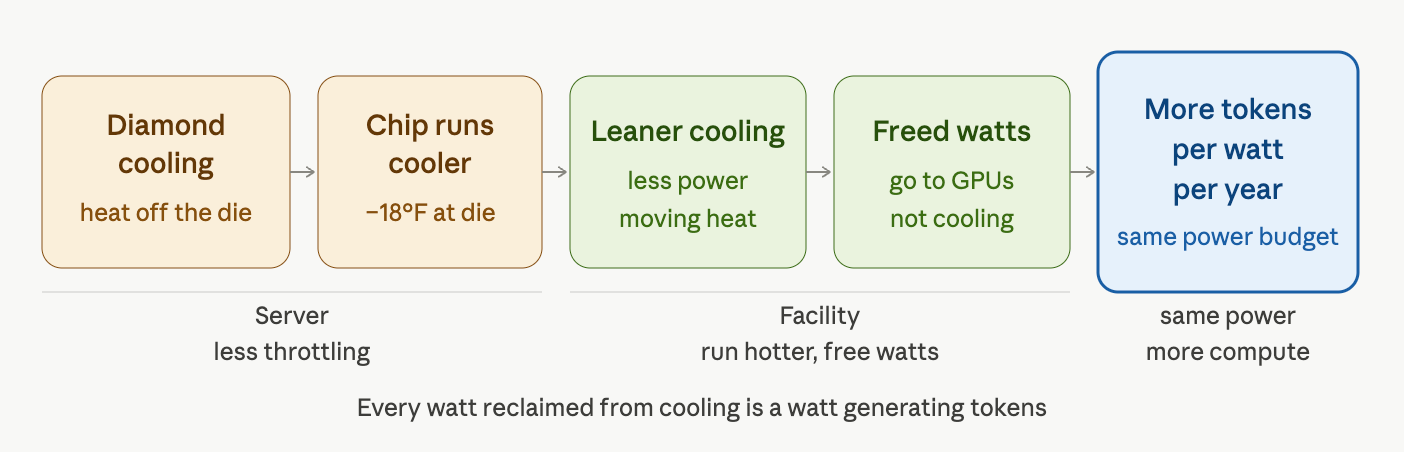
The three-layer (hot) cake:
Layer 1 - Each GPU generation delivers better compute per watt. This cycle runs agnostic of data center operators
Layer 2 - Next edge. Data centers that attack the heat problem at source will run the room warmer and bank the savings back into compute. Same GPUs, same power budget, more throughput
Layer 3 - Got most of the investment first. The hyperscalers are building liquid-cooled by default now

If you have come this far, you’ll like my AI Economics Part 1, Part 2, Part 3 and Part 4 posts