AI economics
This was fun to write.
I’ve been explaining the new AI economics framework to friends over the last couple of weeks. I deconstructed the players and the economics for my own understanding and I thought I could share it here too.
Feel free to reach out if you have any questions.
THE PLAYERS
Every AI lab has its own identity/profile:
OpenAI - 900M+ monthly active users, mostly consumers
Anthropic - 300K+ businesses, 1000+ spending >$1M/year
xAI - massive GPU supply via Colossus but zero demand
This creates different problems:
OpenAI - usage mix problem. High consumer volume and a mix of free and paid users mean low revenue per token and high inference costs to serve. Many users like you and me sending way too many low value prompts compounds fast
Anthropic - GPU supply problem. An enterprise heavy customer base means a great usage mix. High revenue per token and predictable usage patterns mean demand exceeds capacity. Constant rate-limiting
xAI - demand problem. Huge supply with Colossus without model utilization
tldr: Anthropic needs more GPUs. OpenAI needs better quality demand. xAI has supply and no demand.
xAI figured it was easier to generate developer demand through the Cursor partnership/acquisition and monetize extra capacity by leasing some Colossus GPUs to Anthropic.
Meta, Google, Microsoft and Amazon are different beasts:
Google - owns the full stack: TPUs, data centers, cloud and applications (Search, YouTube). Low AI cost structure because it does everything in-house. But every query that goes to ChatGPT or Claude is a lost ad impression. Strategy: (1) defensive via Gemini to protect Search ads (2) offensive via TPUs and Cloud to monetize AI infra demand
Meta - ad revenue ($200B) on platforms AI doesn't threaten. Invested a lot in GPU supply but used for internal ad ranking and recommendations. Open-sourced its own Llama model: one-time training cost, zero ongoing inference cost. The bet: if open-source Llama is 60-90% as good, it creates market pressure that forces OpenAI and Anthropic's inference prices down. The tradeoff is talent- the best researchers want frontier compute not boring ad optimization. Hence the outsized comp to attract talent
Microsoft - cloud infra provider. Bet early by investing billions in OpenAI now worth hundreds of billions. OpenAI is committed to purchasing billions of cloud (Azure) services so Microsoft gets paid regardless of who wins the model race. Strategy: (1) defensive via Copilot embedded across Office, Teams and Windows to protect enterprise software (2) offensive via Azure (Cloud) to monetize infra demand
Amazon - cloud infra provider. Same playbook as Microsoft but bet on both AI models simultaneously. Invested in OpenAI and Anthropic and struck multi-billion AWS cloud deals with both. Indifferent to who wins the model race. Building its own Titanium chips with co-development from Anthropic. Focus is on cloud infrastructure usage. No search, no enterprise or consumer applications to defend or worry about.
THE ECONOMICS
Training vs inference
Training is a one-time capital investment. You build the factory once and it’s a sunk cost. Inference is the factory running 24/7. Every user prompt and model response consumes compute. This compounds with scale and never stops.
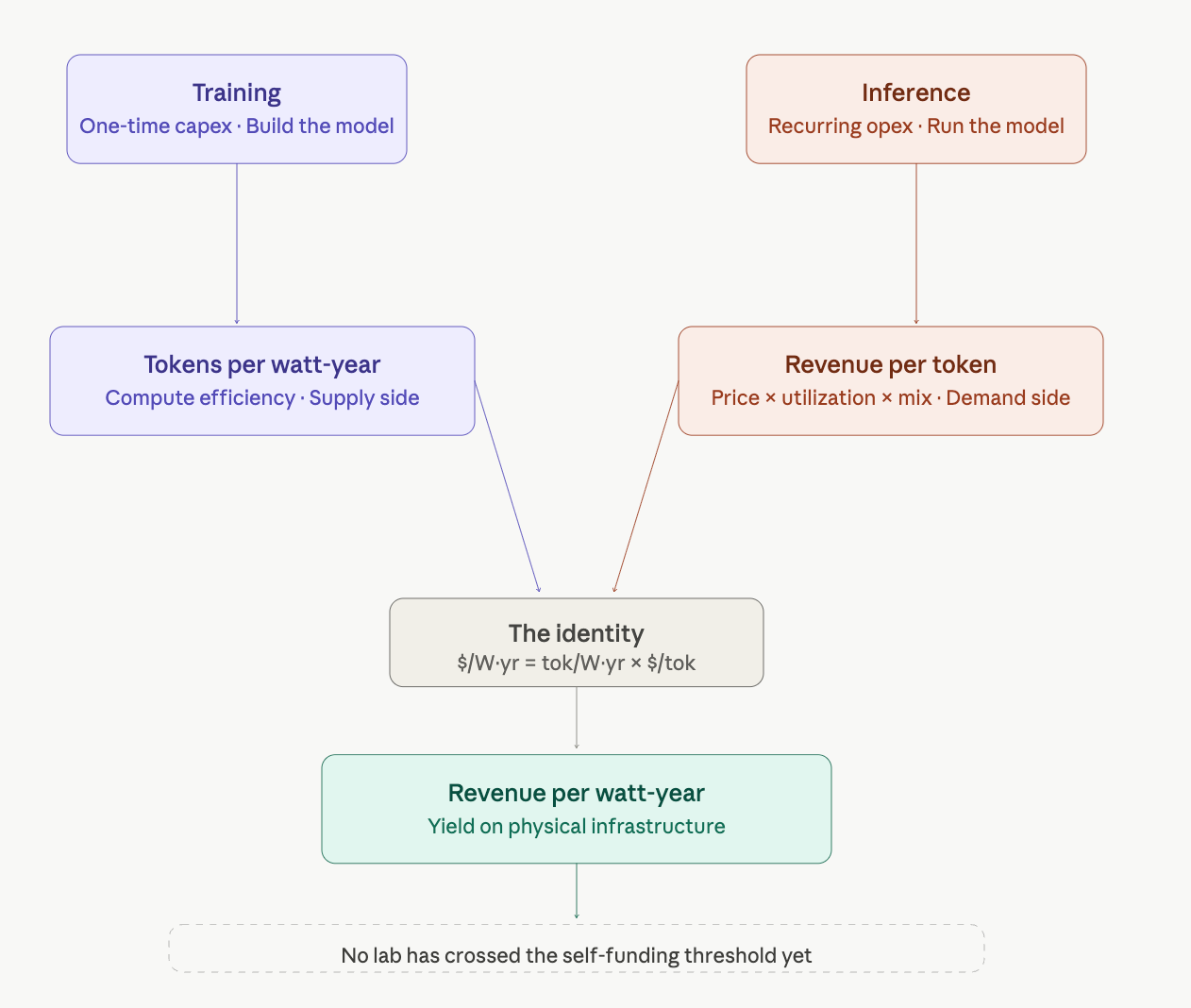
The core metrics:
Tokens per watt-year is a supply side metric. It tells you how much output you’re squeezing from physical infrastructure, eg how much output per unit of sustained power per year. Better hardware, smarter batching, and efficient inference stacks all show up here
Revenue per token is a demand side metric. Price × utilization × mix. This is (1) price per million tokens, eg consumer, businesses, API prices, (2) usage mix, eg individual user vs free user vs paid user vs enterprise user vs API calls, (3) % utilization of compute (eg like hotel occupancy but for GPUs, servers etc)
Revenue per watt-year results from both. What you actually earn per unit of physical infrastructure. This is one number that determines whether a lab can self-fund its next cluster. The other number is cost per watt-year. It matters because each model generation requires more compute than the last.
Jensen from NVIDIA introduced Tokens per Watt x Available Watt at GTC 2026. This only applies to the supply. Revenue per token addresses the demand. Just because you can build more efficient infrastructure and secure more watts, revenue won’t automatically follow. Look at xAI.
Every lab is playing this same game: squeeze more tokens per watt, price highly and acquire more power.
The question is who funds the next cluster - outside capital (investors, IPO, cloud partners, sovereign funds) or self fund in-house through operating profit. No lab has crossed the self-funding threshold yet.
Seeing the delineation between consumer-focused (OpenAI) and enterprise-focused (Anthropic) user bases is key; the operational challenge for $2M-$50M founders is figuring out where to build the initial moat—is it the unique data loop, or the workflow integration? That split dictates everything from talent hiring to necessary compute spend.
Software now has meaningful marginal costs per use and CEOs need to think about unit economics in ways that cloud did not.